OBP Overview
OBP Tutorial: The focus is on offline experimentation with four different components
- The data set component: the pipeline data set.
- The learner or policy component: the policy itself.
- The simulator component: runs the policy.
- The evaluation component: analyzes if the policy compares well with another type of policy or the standard policy.
OBP PROCESS
 From OBP Project
From OBP Project
Data Management
- Datasets
- Bandit Feedback (similar to historial data on SCRUF-D terms).
- Dictionary storing logged data
- Action_context: Context vectors characterizing actions (i.e., a vector representation or an embedding of each action).
- OBP Extension (Slate): Comparison of bandit feedback
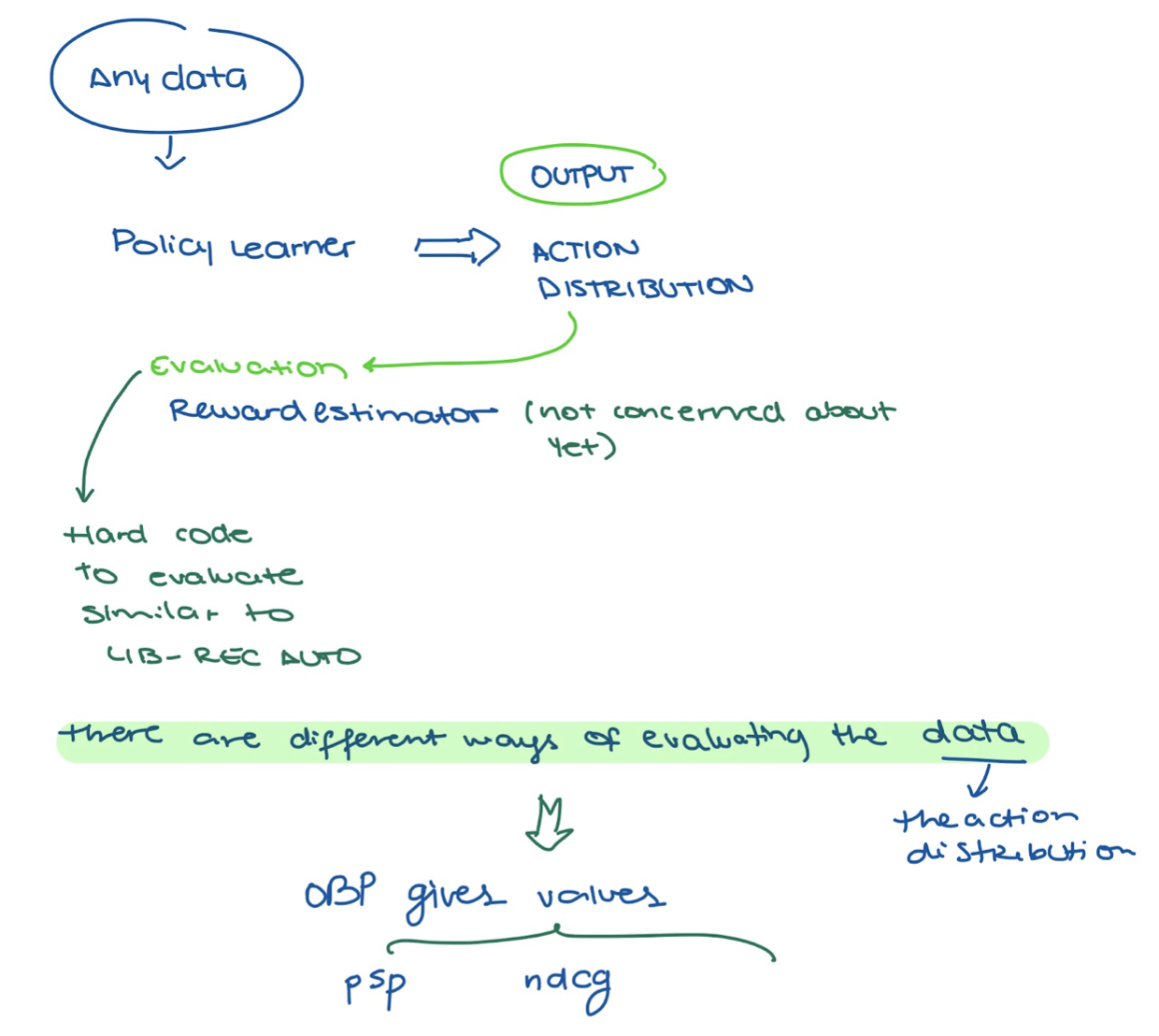
Off-Policy Learner
OBP Off-Policy Learner Notebook
- Class wrapper for ML model
- Example IPWLearner
- Off-policy learner based on Inverse Probability Weighting and Supervised Classification.
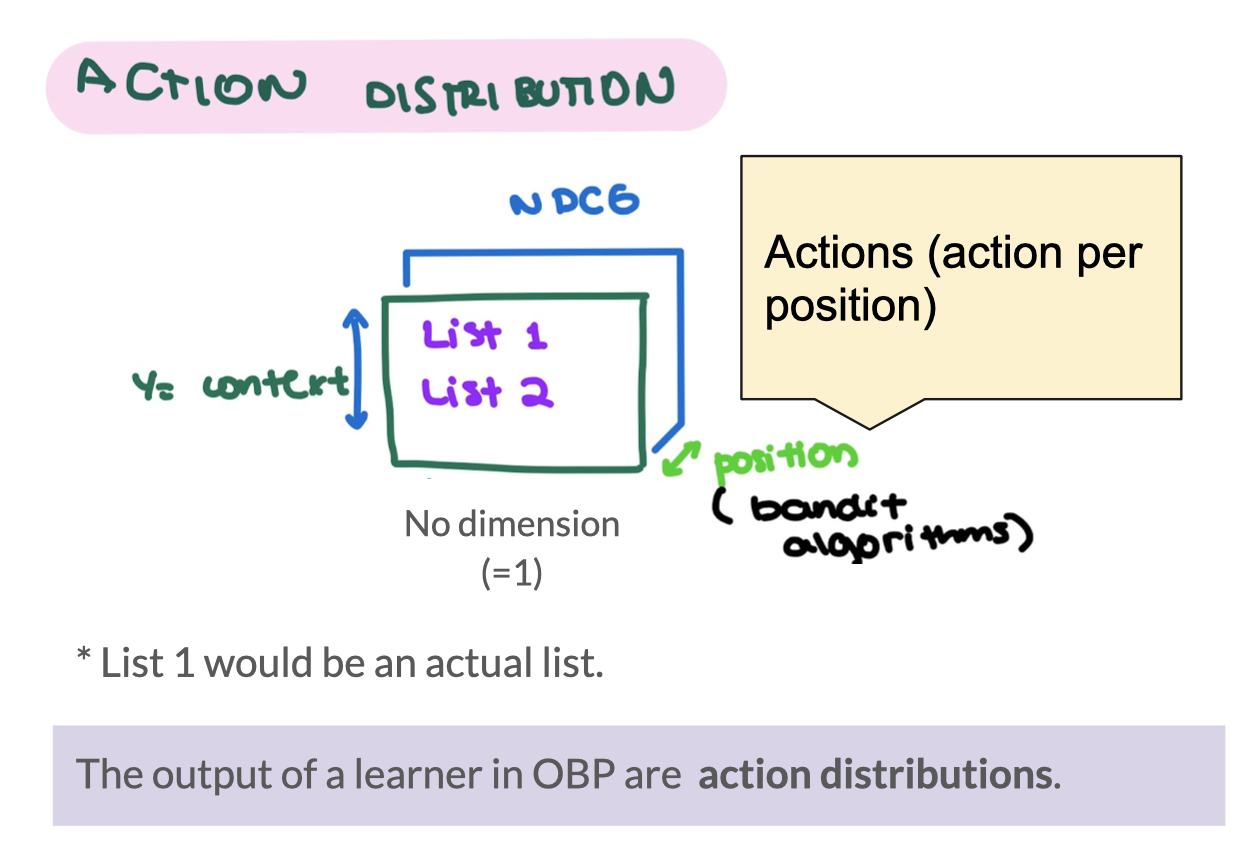
- Outputs
- predictions
- action_probabilty distributions(where len_size = 1)
Simulation
Based on online policy mainly
Off-Policy Estimators (OPE)
- Policy values (metrics) based on reward system
- Return values within [0,1]
- Estimates the performance of a policy based on log history
Additional Notes
OBP Summary Diagram